
이전 포스팅에서 독립실행모드로 하둡을 설치해보았다. 이번 포스팅은 하둡의 3가지 모드 중 가상분산모드로 설치해 볼 것이다. 독립실행모드가 하나의 로컬 환경으로 그냥 하둡을 설치하는 것이라면 가상분산모드는 한 대의 장비로 클러스터를 구성하기 때문에 완전분산모드랑 같은 환경으로 설치할 수 있다. 한 대의 장비지만 클러스터로 구성해서 Single Node Cluster 모드라고도 불린다. 보통 완전분산모드에서 맵리듀스가 잘 돌아가는지 테스트하거나 디버깅하기 위해 많이 쓰는 모드라고 한다.
실행 환경
이전 포스팅에서 Standalone 모드로 구성한 Centos 컨테이너에서 이어서 진행을 할 것이기 때문에 처음부터 시작하는 것이라면 이전 포스팅을 참고하길 바란다.
[Hadoop] 하둡 설치하기 (Standalone)
하둡의 설치 방식에는 총 3가지 버전이 있다. 1. 독립실행모드(Standalone) 2. 가상분산모드(Pseudo-distributed) 3. 완전분산모드(Fully distributed) 이번 포스팅에서는 독립실행모드로 어떻게 설치하는지에
mungiyo.tistory.com
필요 패키지 설치
한 대의 장비로 구성하지만 클러스터이기 때문에 노드들 간의 통신이 요구된다. 하둡에서는 노드들 간의 통신을 ssh을 이용하여 하기 때문에 ssh의 설치가 필수이다.
$ yum install openssh-server openssh-clients openssh-askpass -y
SSH 키 쌍 생성
먼저 SSH 설정을 하기 전 sshd를 실행시키기 위해 다음과 같이 키를 생성해준다.
$ ssh-keygen -f /etc/ssh/ssh_host_rsa_key -t rsa -N ""
$ ssh-keygen -f /etc/ssh/ssh_host_ecdsa_key -t ecdsa -N ""
$ ssh-keygen -f /etc/ssh/ssh_host_ed25519_key -t ed25519 -N ""그리고 ~/.bashrc 에 하단에 /usr/sbin/sshd를 추가해서 로그인될 때마다 sshd를 실행하도록 한다.
# ~/.bashrc
...
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64
export PATH=$PATH:$JAVA_HOME/bin
export JAVA_OPTS="-Dfile.encoding=UTF-8"
export CLASSPATH="."
# 여기서부터 하둡 설정내용
export HADOOP_HOME=/hadoop_home/hadoop-3.3.1
export HADOOP_CONFIG_HOME=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
/usr/sbin/sshd$ source ~/.bashrc
ssh를 비밀번호없이 통신하기 위해 ssh-keygen 을 통해 공개키와 비밀키를 생성한다.
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_dsa이후 생성된 공개키를 인증키로 등록한다.
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keysssh 연결이 잘 되는지 확인하기 위해 다음 명령어를 실행한다.
$ ssh localhost
하둡 설정
hadoop-env.sh 파일을 열어서 다음과 같이 작성해준다.
# 하둡 설정 파일들이 있는 디렉토리로 이동
$ cd $HADOOP_CONFIG_HOME
# hadoop-env.sh 열기
$ vim hadoop-env.sh# hadoop-env.sh
...
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.312.b07-2.el8_5.x86_64
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"그리고 각 데몬들이 홈으로 사용할 디렉토리를 생성합니다.
$ mkdir /opt/hadoop_home/temp
$ mkdir /opt/hadoop_home/namenode
$ mkdir /opt/hadoop_home/datanode다음의 각 파일들을 수정해주어야 합니다.
1. core-site.xml
- HDFS와 MapReduce에서 공통적으로 사용할 환경정보
2. hdfs-site.xml
- HDFS에서 사용할 환경정보
3. mapred-site.xml
- MapReduce에서 사용할 환경정보
이 파일들이 있는 디렉토리로 이동합니다.
$ cd $HADOOP_CONFIG_HOME그 후 각 파일들을 vim 편집기로 열어서 수정합니다.
core-site.xml
$ vim core-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop_home/temp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<final>true</final>
</property>
</configuration>hdfs-site.xml
$ vim hdfs-site.xml<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop_home/namenode_home</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop_home/datanode_home</value>
<final>true</final>
</property>
</configuration>mapred-site.xml
$ vim mapred-site.xml<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
하둡 실행하기
먼저 네임노드를 포맷해준다.
$ hadoop namenode -format진행한 상황을 일단 commit을 하여 이미지를 생성해준다.
# 새로운 터미널에서
$ docker commit hadoop-base centos:hadoop다시 돌아와서 하둡 클러스터를 실행시켜주면 각 노드들이 차례대로 실행된다.
$ start-all.sh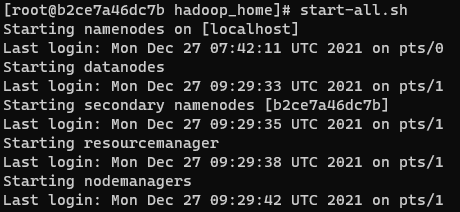
jps 명령어로 jvm 위에서 실행되고 있는 노드들을 확인할 수 있다.
$ jps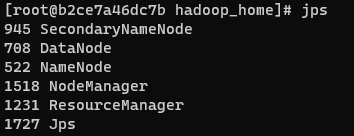
맵리듀스 테스트
$HADOOP_HOME 경로의 NOTICE.txt 파일을 WordCount를 해보겠다.
$ cd $HADOOP_HOME
$ ls
bin include libexec licenses-binary logs NOTICE.txt sbin wordcount_output
etc lib LICENSE-binary LICENSE.txt NOTICE-binary README.txt share먼저 HDFS에 NOTICE.txt 파일을 올린다.
$ hadoop fs -mkdir /test
$ hadoop fs -put NOTICE.txt /test
$ hadoop fs -ls /test
Found 1 items
-rw-r--r-- 1 root supergroup 1541 2021-12-31 03:36 /test/NOTICE.txt하둡에서 기본적으로 제공하는 jar 파일을 이용해서 WordCount 예제를 돌려보겠다.
$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount /test /test_out이후 WordCount를 실시한 결과를 확인할 수 있다.
$ hadoop fs -ls /test_out
Found 2 items
-rw-r--r-- 1 root supergroup 0 2021-12-31 03:39 /test_out/_SUCCESS
-rw-r--r-- 1 root supergroup 1402 2021-12-31 03:39 /test_out/part-r-00000
$ hadoop fs -cat /test_out/*
(BIS), 1
(ECCN) 1
(TSU) 1
(http://www.apache.org/). 1
(see 1
--------------------- 1
2006 1
5D002.C.1, 1
740.13) 1
<http://www.wassenaar.org/> 1
APIs 1
Administration 1
Apache 4
BEFORE 1
BIS 1
Bouncy 1
...
Web UI로 모니터링하기
하둡에서는 Web UI를 이용한 모니터링을 지원한다. Web UI의 포트번호는 9870을 사용한다. (hadoop 3.x 기준) 아까 commit한 이미지를 이용해 컨테이너를 포트포워딩하여 접속해보자.
$ docker run -it --name hadoop-base -p 9870:9870 centos:hadoop호스트의 9870포트를 컨테이너의 9870포트와 포트포워딩을 하여 컨테이너를 실행했다. 이제 하둡을 켜서 Web에 접속해보자.
$ start-all.sh그리고 localhost:9870 으로 접속하면 Web UI를 확인할 수 있다.
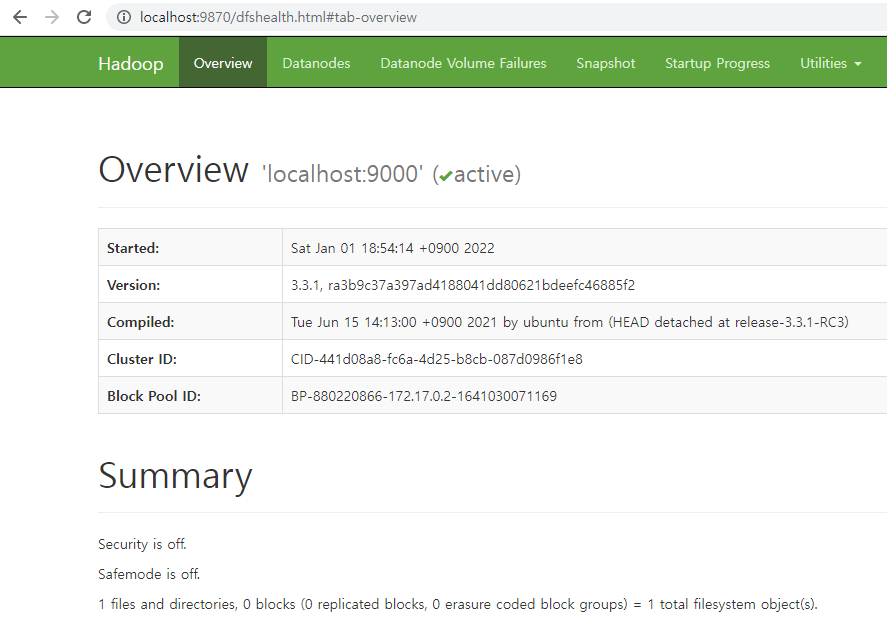
'Data > Hadoop' 카테고리의 다른 글
| [Hadoop] 도커(Docker)로 하둡 설치하기 (Fully-distributed) (4) | 2022.05.12 |
|---|---|
| [Hadoop] 도커(Docker)로 하둡 설치하기 (Standalone) (2) | 2021.12.23 |