
물리 엔진과 오브젝트 용어
DB 엔진 용어
- MySQL이라는 DBMS는 MySQL Engine과 Storage Engine으로 구성되어 있다.
- MySQL 엔진(MySQL Engine)
- 파서(parser)
- 전처리기(preprocessor)
- 옵티마이저(optimizer)
- 엔진 실행기(engine executor)
- 스토리지 엔진(Storage Engine)
- InnoDB, MyISAM, Memory 등
스토리지 엔진
- 사용자가 요청한 SQL 문을 토대로 DB에 저장된 디스크나 메모리에서 필요한 데이터를 가져오는 역할.
- 이후 해당 데이터를 MySQL 엔진으로 보내준다.
- 스토리지 엔진이 데이터를 저장하는 방식에 따라 각각의 스토리지 엔진을 선택하여 사용할 수 있다.
- 필요하다면 외부에서 스토리지 엔진 설치 파일을 가져와 활성화하여 즉시 사용할 수 있다.
- 일반적으로는 온라인상의 트랜잭션 발생으로 데이터를 처리하는 OLTP환경이 대다수인 만큼 주로 InnoDB 엔진을 사용한다.
- 이 외에도 대량의 쓰기 트랜잭션이 발생하면 MyISAM 엔진을, 메모리 데이터를 로드하여 빠르게 읽는 효과를 내려면 Memory 엔진을 사용하는 식으로 응용하여 스토리지 엔진을 선택할 수 있다.
SELECT ENGINE, TRANSACTIONS, COMMENT
FROM information_schema.ENGINES;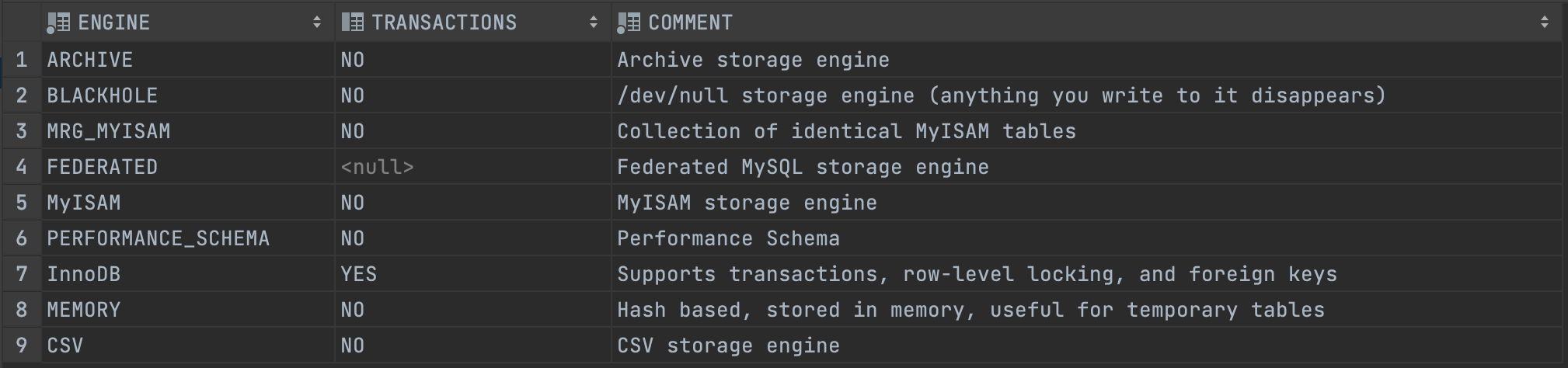
MySQL 엔진
- 사용자가 요청한 SQL 문을 넘겨받은 뒤 SQL 문법 검사와 적절한 오브젝트 활용 검사를 하고, SQL 문을 최소 단위로 분리하여 원하는 데이터를 빠르게 찾는 경로를 모색하는 역할을 수행한다.
- 이후 스토리지 엔진으로부터 전달받은 데이터 대상으로 불필요한 데이터는 제거하거나 가공 및 연산하는 역할을 한다.
- 즉, SQL 문의 시작 및 마무리 단계에 MySQL 엔진이 관여하며, 스토리지 엔진으로부터 필요한 데이터만을 가져오는 핵심 역할을 담당한다.
SQL 프로세스 용어

- 사용자가 SQL 문을 수행하면, 파서는 MySQL이 이해할 수 있는 최소 단위로 구성요소를 분리하고 해당 구성요소를 트리로 만든다. 트리를 만드는 과정에서는 문법 오류가 있는지 검토한다.
- 트리의 최소 단위는 >, <, = 등의 기호나 SQL 키워드로 분리한다. 만약 트리에 허용되지 않는 문법이 포함된다면 에러 발생과 동시에 실행이 종료된다.
- 이후 전처리기는 생성된 트리 결과를 토대로, 이미 만들어진 테이블이나 뷰 등으로 구성되지는 않는지, 존재하지 않는 열을 포함하지는 않는지, 조회 권한이 없는 테이블을 조회하는지 등 유효성을 검증한다.
- 만약 유효하지 않은 오브젝트가 있거나 권한이 없는 오브젝트를 호출하면 바로 에러를 발생하여 사용자에게 표시한다.
- 다음, 옵티마이저는 트리를 구성하는 오브젝트의 데이터를 효율적으로 가져오기 위해 시간은 적게 소요되면서도 비용 효율적인 경로로 데이터를 검색하는 방법에 관한 실행 계획을 수립한다.
- 엔진 실행기는 이전에 수립된 실행 계획으로 스토리지 엔진을 호출해 필요한 데이터를 가져온다. 이후 엔진 실행기는 스토리지 엔진을 통해서 가져온 데이터 중 불필요한 데이터를 필터링하여 사용자가 원하는 결과를 전달한다.
파서
- 사용자가 요청한 SQL문을 쪼개 최소 단위로 분리하고 트리를 만든다.
- 트리를 만들면서 문법 검사를 수행한다.
전처리기
- 파서에서 생성한 트리를 토대로 SQL 문에 구조적인 문제가 없는 파악한다.
- SQL 문에 작성된 테이블, 열, 함수, 뷰와 같은 오브젝트가 실질적으로 이미 생성된 오브젝트인지, 접근 권한은 부여되어 있는지 확인하는 역할을 한다.
옵티마이저
- DBMS의 두뇌라고 불러도 과언이 아닐 만큼 핵심적인 역할을 수행한다.
- 전달된 파서 트리를 토대로 필요하지 않은 조건은 제거하거나 연산 과정을 단순화한다. 나아가 어떤 순서로 테이블에 접근할지, 인덱스를 사용할지, 사용한다면 어떤 인덱스를 사용할지, 정렬할 때 인덱스를 사용할지 아니면 임시 테이블을 사용할지와 같은 실행 계획을 수립한다.
- 단, 실행 계획으로 도출할 수 있는 경우의 수가 지나치게 많을 때는 실행 계획을 수립하고 비용을 산정하여 최적의 실행 계획을 선택하기까지 시간이 오래 걸리는 만큼 모든 실행 계획을 판단하지는 않는다.
- 이는 옵티마이저가 선택한 최적의 실행 계획이 최상의 실행 계획이 아닐 가능성도 있다는 걸 의미한다.
- 실행 계획을 수립하는 작업 자체만으로도 사용자의 대기 시간과 하드웨어 리소스를 점유하므로, 시간과 리소스에 제한을 두고 실행 계획을 선정해야 한다.
엔진 실행기
- MySQL 엔진과 스토리지 엔진 영역 모두에 걸치는 오브젝트로, 옵티마이저에서 수립한 실행 계획을 참고하여 스토리지 엔진에서 데이터를 가져온다.
- 이후 MySQL 엔진에서는 읽어온 데이터를 정렬하거나 조인하고, 불필요한 데이터는 필터링 처리하는 추가 작업을 한다.
- 따라서 MySQL 엔진의 부하를 줄이려면 스토리지 엔진에서 가져오는 데이터양을 줄이는 게 매우 중요하다.
DB 오브젝트 용어
- 데이터베이스를 구성하는 요소 중 하나로 오브젝트라 불리는 객체들이 있다.
- 테이블(table)
- 로우[행](row)
- 컬럼[열](column)
- 기본 키(primary key)
- 외래 키(foreign key)
- 인덱스(index)
- 뷰(view)
테이블
- 테이블은 데이터를 저장하는 오브젝트로 행과 열의 정보를 담는다. RDB인 MySQL은 2차원 배열 형태로 테이블을 관리한다.
- 테이블에서는 저장 방식과 저장 구조에 따라 스토리지 엔진 속성을 정의할 수 있다.
- InnoDB 스토리지 엔진은 보통 OLTP 환경에서 주로 사용하는 기본 DB 엔진이며 그 외에도 MyISAM, Memory, Blackhole 엔진 등이 있다.
로우[행]
- 로우는 행에 해당하는 용어로, 테이블에서 동일한 구조의 데이터 항목들의 집합을 가리킨다.
- 행 수가 많아지면 데이터에 접근하는 과정에서 시간이 오래 소요될 가능성이 높다. 이때 파티셔닝(partitioning) 기법으로 SQL 문의 성능 향상을 검토해볼 수 있다.
컬럼[열]
- 컬럼은 열에 해당하는 용어로, 사전에 정의한 데이터 유형으로 데이터값을 저장하며, 열별로 다른 데이터 유형을 가질 수 있다.
기본 키
- 기본 키(PK)는 특정 행을 대표하는 열을 가리키는 용어로 주 키라고도 한다.
- MySQL에서 기본 키는 클러스터형 인덱스(clustered index)로 작동하는데, 이는 기본 키의 구성 열 순서를 기준으로 물리적인 스토리지에 데이터가 쌓인다는 뜻이다.
- 비슷한 기본 키 값들이 근거리에 적재되므로 기본 키를 활용하여 인덱스 스캔을 수행하면 테이블 데이터에 더 빠르게 접근할 수 있다.
기본 키와 똑같은 인덱스를 생성하면 인덱스가 저장되는 물리적 공간이 낭비되는 한편 데이터의 삽입/삭제/수정에 따른 인덱스 정렬의 오버헤드가 발생한다.
외래 키
- 외래 키(FK)는 외부에 있는 테이블을 항상 참조하면서, 외부 테이블의 데이터가 변경되면 함께 영향을 받는 관계를 설정하는 키이다.
인덱스
- 인덱스는 데이터베이스에서 키값으로 실제 데이터 위치를 식별하고 데이터 접근 속도를 높이고자 생성되는, 키 기준으로 정렬된 오브젝트이다.
- 인덱스는 생성하려는 열의 속성에 따라 고유 인덱스(unique index)와 비고유 인덱스(non-unique index)로 구분할 수 있다.
- 고유 인덱스
- 고유 인덱스란 말 그대로 인덱스를 구성하는 열들의 데이터가 유일하다는 의미이다.
- 차례로 정렬되는 인덱스 열의 데이터는 서로 중복되지 않고 유일성을 유지한다.
- 만약 동일한 데이터가 생성되면 고유 인덱스의 중복 체크 과정에서 에러가 발생한다.
- 중복이 없는 열들을 고유 인덱스로 생성하려 한다면 중복이 있는지 검증하는 절차를 거쳐야 하므로, 불필요한 중복 검증 과정이 추가되니 주의해야 한다.
- 기본 키와 고유 인덱스의 차이점
- 기본 키에는 NULL을 입력할 수 없지만 고유 인덱스는 상관이 없다.
ALTER TABLE <TABLE_NAME>
ADD UNIQUE INDEX <인덱스명>(<컬럼명>);- 비고유 인덱스
- 비고유 인덱스는 고유 인덱스에서 데이터의 유일한 속성만 제외한 키이다.
- 데이터가 신규 입력되어 인덱스가 재정렬되더라도 인덱스 열의 중복 체크를 거치지 않고 단순한 정렬 작업을 수행한다.
ALTER TABLE <TABLE_NAME>
ADD INDEX <인덱스명>(<컬럼명>);뷰
- 뷰는 일명 가상 테이블이다.
- 실제로 테이블이 생성되는 것이 아니고 특정 정보를 외부에 직접적으로 공개하지 않고 제한된 정보만을 제공할 수 있다.
- 실제 테이블을 변경하면 뷰에서도 확인할 수 있으며, 뷰에서 데이터를 변경하면 실제 테이블의 데이터도 변경 된다.
뷰를 사용하는 이유
뷰를 사용하는 이유는 일부 데이터에 대해서만 데이터를 공개하고, 노출에 민감한 데이터에 대해서는 제약을 설정할 수 있는 보안성 때문이다. 한편 여러 개의 테이블을 병합(join)해서 활용할 떄는 성능을 고려한 최적화된 뷰를 생성함으로써 일관된 성능을 제공할 수 있다.
'Language > SQL' 카테고리의 다른 글
| SQL 튜닝 용어 정리(3) (0) | 2023.04.04 |
|---|---|
| SQL 튜닝 용어 정리(2) (0) | 2023.04.04 |