
개요
Elasticsearch는 실시간 검색이 가능하도록 하기 위해 색인(indexing)이라는 과정이 필요한데 이것을 Elasticsearch는 내부적으로 어떤 처리를 하는 지 알기 위해 오늘은 Elasticsearch 색인 과정에 대해 포스팅 하도록 하겠습니다. (본 내용은 Elasticsearch에 대해 기본적인 이해가 있다고 가정하고 작성하였습니다.)
Elasticsearch Cluster
색인 과정을 알아보기 전에 Elasticsearch는 데이터를 어떻게 저장하는 지 알아보겠습니다. Elasticsearch는 Index 라는 단위를 많이 사용하는데 Index란 RDB와 비교하자면 테이블과 비슷합니다. Elasticsearch는 Index를 여러 개로 쪼개서 여러 노드에 분산하여 저장하는데 이 쪼개진 단위 하나를 Primary Shard 라고 부르고 노드가 고장났을 때 데이터 손실을 막기 위해 복제본 Shard를 만들어 두는데 해당 Shard를 Replica 라고 부릅니다. 해당 샤드들은 각 노드에 분산 되어 저장되어 노드에 결함이 생겨도 데이터 손실 없이 정상적으로 동작할 수 있도록 해줍니다.

Elasticsearch Index
그럼 Index는 내부적으로 어떻게 구현되어 있나? Index는 내부적으로 Apache Lucene의 Lucene Index 라는 구현체로 이루어져 있습니다. 갑자기 Apache Lucene이 왜 나오냐를 따져보면 기본적으로 Java의 라이브러리인 Apache Lucene은 Single Node 기반이기 때문에 Multi-Node가 불가능했는데 Elasticsearch에서 Apache Lucene을 Core Engine으로 사용하면서 Multi-Node가 가능하도록 만들었기 때문에 내부적으로는 Apache Lucene을 사용합니다. 또한, Lucene Index는 여러 개의 Lucene Segment로 나누어지게 되고 해당 Lucene Segment 들은 여러 개의 노드에 분산 저장되게 됩니다.

Elasticsearch Indexing Process
그러면 이제 본격적으로 색인 과정에 대해 알아봅시다.
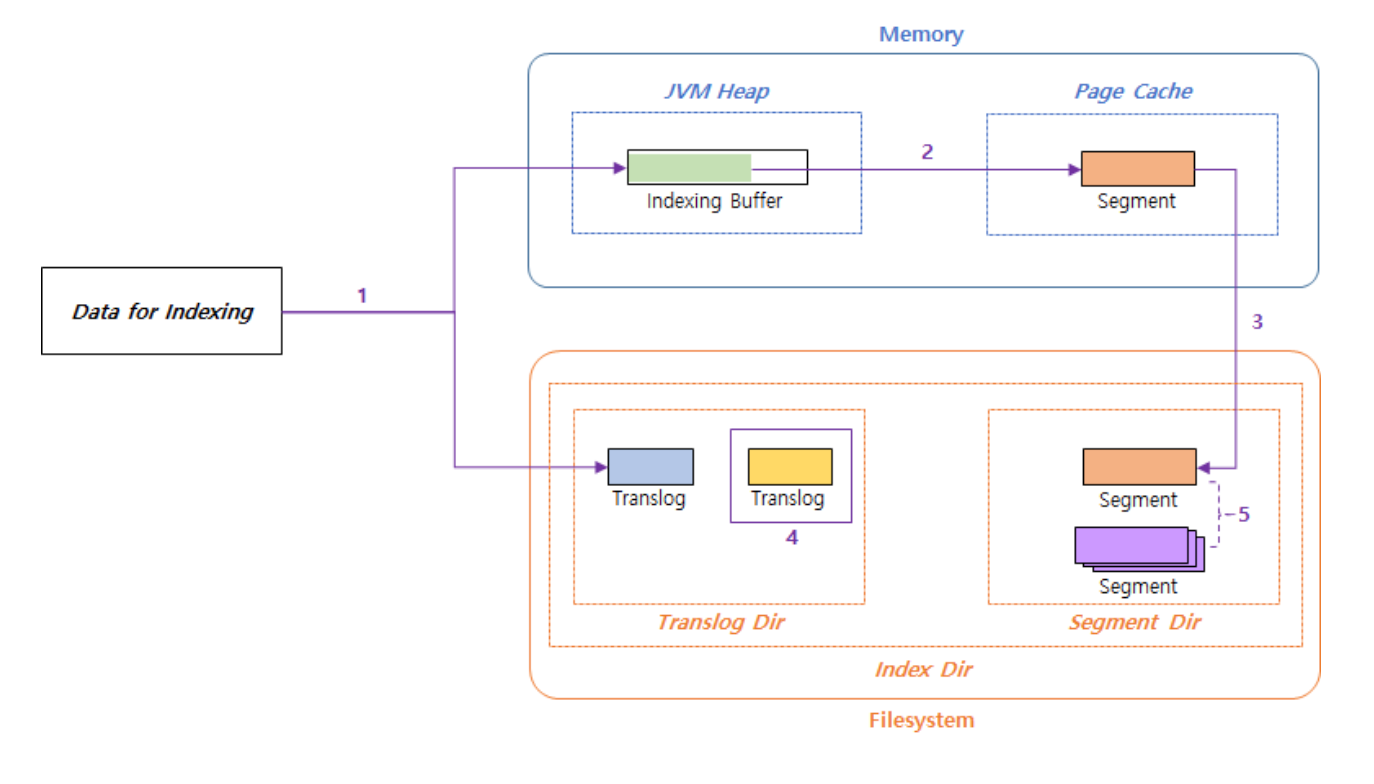
위 그림은 Elasticsearch 색인 프로세스의 전체적인 그림입니다. 전체적인 흐름을 이해하기 좋아서 가져와봤는데 색인 프로세스는 두 가지로 나눌 수 있습니다. 첫 번째는 검색이 가능한 상태가 되기 까지의 과정, 두 번째는 실제 데이터가 저장되기 까지의 동작, 마지막으로 index 최적화 동작입니다. 먼저 설명할 과정은 검색이 가능한 상태가 되기 까지의 과정입니다.
검색이 가능한 상태가 되기 까지의 과정
검색 엔진으로 Elasticsearch를 많이 사용하는데 우리가 실제로 데이터를 Elasticsearch에 넣었을 때 바로 검색이 안되는 경우가 종종 있었을 것입니다. 이것은 Elasticsearch가 내부적으로 색인(indexing)이라는 프로세스를 하기 때문인데 해당 과정이 완료되지 않으면 검색을 할 수가 없습니다. 그렇다면 내부적으로 무슨 프로세스를 하는 지 알아보겠습니다.
Step 1
REST API를 통해 데이터를 index에 삽입했을 때
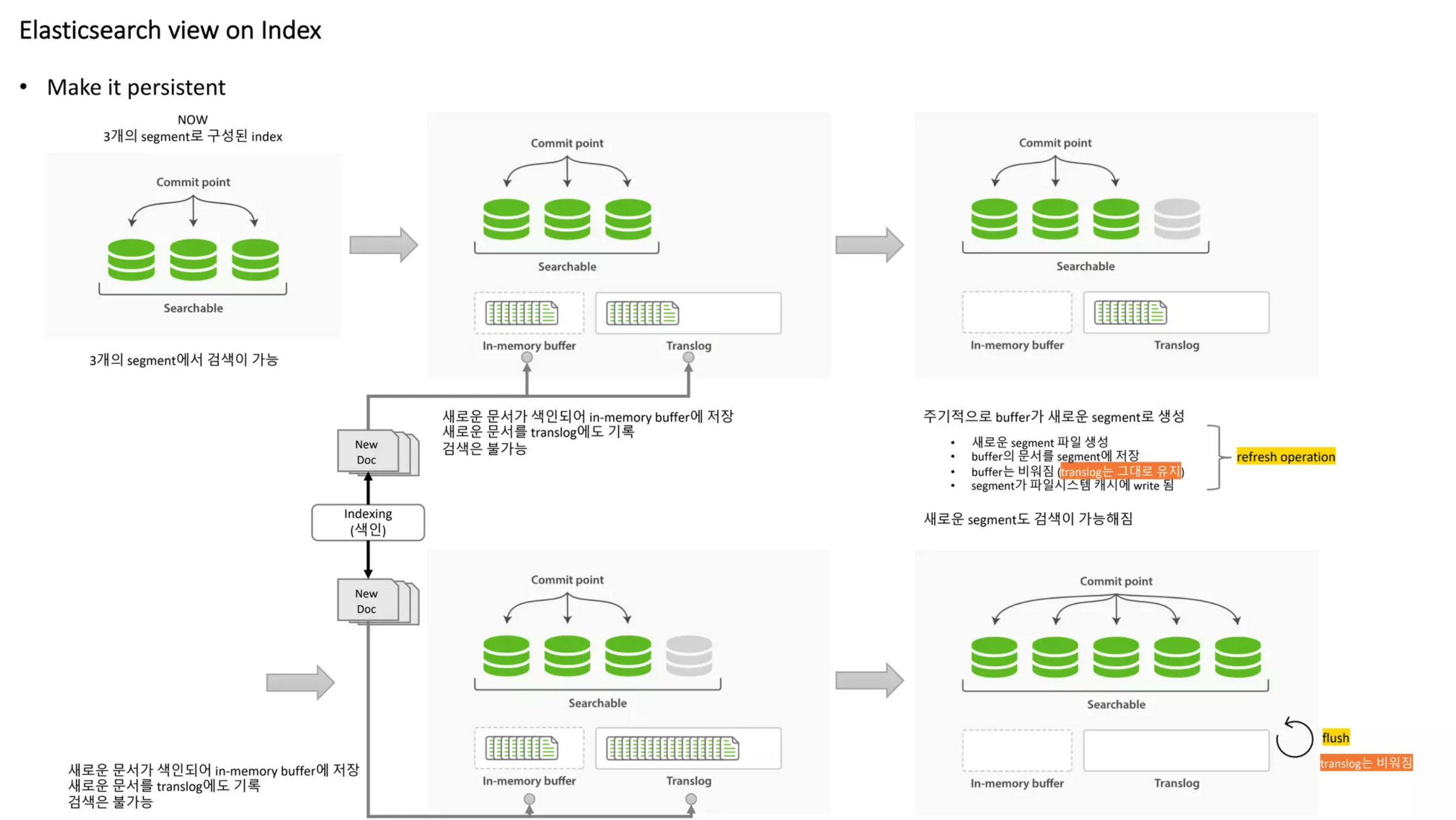
- 해당 데이터는 Indexing Buffer라는 In-memory buffer에 Inverted Index Data로 변환 되어 저장되게 됩니다.
- Inverted Index 는 Lucene Index가 생성하여 사용하는 데이터 입니다.
- 동시에 해당 데이터는 Translog 라는 파일에 기록이 됩니다.
본 스탭이 완료되면 REST API에 대한 Request에 대해 Response를 받게 됩니다.
Step2
Indexing Buffer의 데이터를 Segment 라는 Index File Format으로 변환하여 Page Cache에 저장하게 됩니다.
- 해당 과정에서 write() 라는 시스템 콜을 사용하게 됩니다.
- write는 디스크에 데이터를 쓰도록 요청하는 시스템 콜인데 Disk I/O는 리소스가 많이 소모되는 작업이기 때문에 그래서 OS는 먼저 해당 데이터를 메모리 상의 Page Cache 라는 곳에 저장해놓고 이후에 디스크에 쓰는 작업을 하게 됩니다. 그리고 시스템 콜 요청자는 Page Cache에 데이터가 저장됐을 때 응답을 받게 됩니다.
- Page Cache에 저장된 Segment의 Indexing Data는 검색이 가능하며 해당 Segment는 uncommited 상태가 됩니다.
본 Step의 Trigger 조건
- Indexing Buffer가 Full 상태가 될 경우
- refresh_interval을 통해 설정된 주기가 만료되었을 경우 (default : 1초)
- ES_API(_refresh)의 명시적인 호출
본 스탭이 완료되면 indexing된 데이터는 검색이 가능한 상태가 됩니다.
해당 과정까지 완료 되면 우리는 indexing data를 검색할 수 있게 되고 이후 과정은 Elasticsearch의 실제 데이터가 저장되기 까지의 동작으로 이해하면 됩니다.
실제 데이터가 저장되기 까지의 동작
Elasticsearch는 실제 검색이 가능한 상태가 되도록 한 이후 해당 데이터들을 영구적으로 저장하고 저장 공간에 대한 최적화도 하게 되는데 해당 과정에 대해 설명해 보도록 하겠습니다.
Step3
Step2에서 Page Cache에 저장한 Segment 파일을 실제 FileSystem에 저장하는 작업입니다.
- 해당 작업은 fsync() 라는 시스템 콜을 통해 진행됩니다.
- 해당 데이터들을 디스크에 저장되도록 요청하며 해당 작업이 끝날 때까지 대기합니다.
- Disk I/O 가 발생하므로 리소스가 많이 소모됩니다.
- FileSystem에 저장된 후 해당 Segment 들은 commited 상태가 됩니다.
본 스탭의 Trigger 조건
- Page Cache가 Full 상태이며 OS 알고리즘에 의해 선택된 경우
- Elasticsearch의 Flush 주기가 만료된 경우
- ES API(_flush)의 명시적인 호출
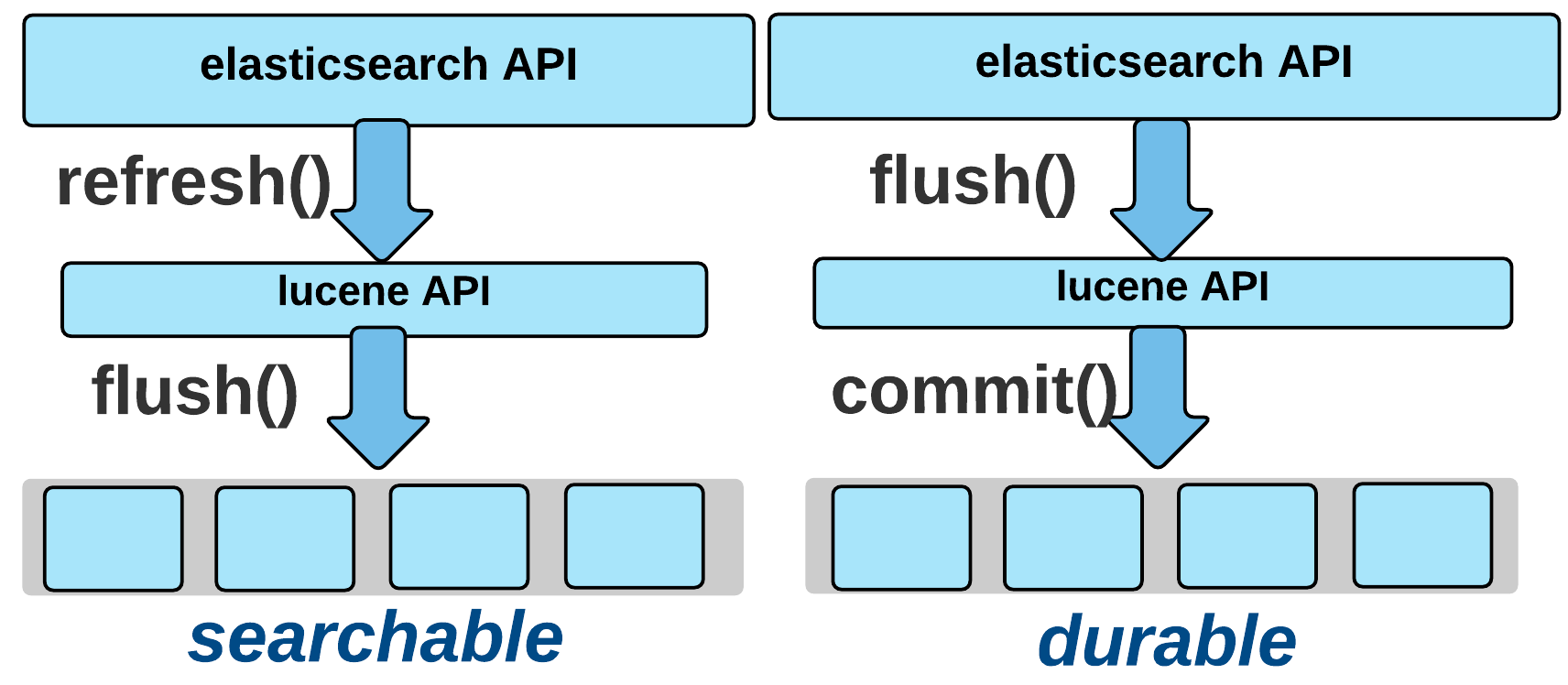
Step4
Step3가 정상적으로 완료되면 Translog를 새로 작성하게 됩니다.
- 이후에 들어오는 indexing data들은 새로 작성된 Translog에 기록됩니다.
- Translog?
- Elasticsearch에 색인되는 Transaction Log가 기록되는 파일입니다.
- Disk에 Segment를 저장하기 전에 먼저 Page Cache라는 메모리 영역에 저장하고 Lucene API를 통해 commit()이 이루어질 때 해당 데이터들을 실제 Disk에 쓰기 때문에 commit이 발생하기 이전의 데이터들은 해당 노드에 장애가 발생하면 손실되기 때문에 해당 상황을 방지하기 위해 기록됩니다.
- 실제 commit이 되기 전에 장애가 발생할 시 해당 Translog를 통해 복구가 이루어집니다.
Translog | Elasticsearch Guide [8.9] | Elastic
Changes to Lucene are only persisted to disk during a Lucene commit, which is a relatively expensive operation and so cannot be performed after every index or delete operation. Changes that happen after one commit and before another will be removed from th
www.elastic.co
여기까지의 Step은 아래 그림으로 표현할 수 있습니다.
index 최적화 동작
Elasticsearch는 색인된 Segment를 삭제하면 "deleted" 표시를 하고 물리적으로 디스크에서 삭제하지는 않는다. 그렇기 때문에 시간이 지나면 Segment들이 쌓이게 되는데 이는 검색 성능을 저하하고 저장 공간을 낭비하기 때문에 주기적으로 Merge 라는 작업이 이루어집니다.
- Merge?
- 비슷한 크기의 Segment를 하나의 Segment로 통합하는 과정
- 해당 과정에서 deleted 표시된 Segment는 통합하는 과정에서 물리적으로 삭제가 됩니다.
Merge | Elasticsearch Guide [8.9] | Elastic
A shard in Elasticsearch is a Lucene index, and a Lucene index is broken down into segments. Segments are internal storage elements in the index where the index data is stored, and are immutable. Smaller segments are periodically merged into larger segment
www.elastic.co
Step5
Step5는 해당 Merge 작업을 실행하는 스탭입니다.
- 해당 인덱스 샤드들에 대한 Merge를 Merge Scheduler에 등록합니다.
- Merge Policy에 따라 해당 인덱스 샤드의 Segment들이 Merge가 필요한 지 체크한 후 Merge를 수행합니다.
- 해당 Segment들은 새로 생성된 Segment들이 아닌 Merge Policy에 의해 선택된 Segment들 입니다.
