안녕하세요. 오랜만에 글을 씁니다. 이번 포스팅은 2025년 9월부터 구축했었던 MySQL, PostgreSQL -> Databricks 의 CDC 파이프라인 구축 경험에 대해 글을 쓰려고 합니다.
배경
현 회사에서 기존에 CDC 파이프라인으로 Airbyte 를 운영하고 있었습니다. 먼저, Airbyte 에 대해 간략히 설명하자면 배치 기반 ELT 플랫폼으로 다양한 Source 의 데이터를 Destination 으로 데이터를 수집할 수 있는 파이프라인을 No Code 수준으로 구축할 수 있는 오픈소스 툴입니다.
위와 같은 점을 활용하여 간편하게 파이프라인을 구축할 수 있었으나 운영 중 다음과 같은 한계를 직면했었습니다.
먼저 저희는 MySQL 과 PostgreSQL 을 주로 Service DB 로 사용 중이었고 해당 데이터를 Databricks 로 끌어오기 위해 MySQL Connector 와 PostgreSQL Connector 를 사용하여 CDC 방식을 사용하여 데이터를 수집하고 Databricks Connector 를 통해 Databricks 의 Delta Table 형태로 데이터를 복제하는 파이프라인을 구축하여 사용했습니다.
이때, 새로운 테이블을 추가하거나 할 때 Airbyte 는 CDC 이전 과거 데이터를 채우기 위해 스냅샷이라고 부르는 소스 DB에 Full Scan 방식으로 조회 쿼리를 날리게 되는데 이는 소스에 부하를 많이 줄 수 있었고 Single Thread 방식으로 실행하기 때문에 대용량 테이블의 경우 시간이 매우 오래 걸리는 이슈가 있었습니다. 그리고 최악의 경우 테이블의 크기가 매우 크다면 스냅샷 시간이 길어져 MySQL 의 경우 binlog, PostgreSQL 의 경우 WAL 의 Retension 기간이 만료되어 변경 사항 로그가 유실될 수도 있습니다.
또한 Databricks Connector 를 통해 Databricks 에 적재할 때 저희는 SQL Warehouse 를 사용했는 데 Connector 는 내부적으로 JDBC 를 통해 굉장히 많은 쿼리를 SQL Warehouse 에 날리는 구조로 되어 있었습니다. 어느 날 Databricks 쪽 API 에 문제가 생겼는 지 Connector 에서 JDBC 에서 Read Timeout 이 발생하면서 파이프라인이 실패하게 되는 현상이 발생하면서 Databricks 가 정상화되기까지 대부분 파이프라인이 제대로 동작하지 않아 하루 정도 데이터를 Sync 하지 못했던 상황이 있었습니다.
그리고 추후 Online Feature Store 나 실시간 데이터 연동이 필요할 경우 Airbyte 의 배치 방식에는 해당 요구사항을 충족하기 어려웠기 때문에 새롭게 CDC 파이프라인을 구축하기로 결정했습니다.
CDC 란?
설명하기에 앞서 보통 데이터 웨어하우스 구축을 위해 여러 DB의 데이터를 하나의 저장소로 통합하는 작업을 위해 ETL 파이프라인을 구축하는 경우가 많은데 이를 위해서는 보통 두 가지 방법이 있습니다. DB 의 데이터를 SQL 을 통해 Query 하여 해당 결과 데이터를 직접 수집하는 방식과 DB 의 binlog 나 WAL 과 같은 log 를 활용하여 데이터를 수집하는 방법이 있습니다.
보통 Query 를 활용하여 특정 테이블에 SELECT 문을 통해 데이터를 읽어서 해당 결과값을 그대로 적재하는 경우가 많은데 해당 방식은 구현이 간단한다는 장점이 있지만 DB 의 성능에 영향을 많이 받으며 특히 대용량 테이블의 경우에는 한 번 데이터를 가져올 때마다 Slow Query 형태가 되어 리소스를 점유하며 대량의 Disk I/O 가 발생하게 됩니다. 이는 해당 DB 에 무리한 부하를 주게 되며 Production 의 경우에는 서비스에 지장이 갈 수도 있게 됩니다.
그래서 이러한 문제를 해결하기 위해 여러 DB 에서는 Query 기반이 아닌 로그 기반으로 DB 의 리소스를 거의 사용하지 않으면서 데이터를 복제할 수 있도록 하는 기술들을 제공하는데 이를 CDC 라고 합니다. 정확한 정의로 CDC 는 Change Data Capture 의 약자로 데이터베이스(DB) 내 데이터의 삽입, 수정, 삭제 등 변경사항을 실시간으로 추적하고 감지하여 다른 시스템으로 자동 전송하는 기술로 저는 이를 활용하여 DB 의 데이터를 Databricks 로 통합하는 파이프라인을 구축하고자 합니다.
CDC Tool 선정
데이터베이스의 CDC 데이터를 정형화된 포맷으로 변환하여 수집할 수 있게 해주는 Tool 이 여러가지 존재하는데 대표적으로는 두 가지 정도가 존재하는데 Debezium 과 Flink CDC 입니다.
먼저 Debezium 은 Kafka Connect 위에서 동작하는 여러 Source Connector 를 제공하는 대표적인 CDC 플랫폼입니다. DB 의 CDC 데이터를 수집하여 정형화된 포맷으로 변환하여 Kafka 에 Message 형태로 수집할 수 있는데 CDC 이벤트를 표준환된 포맷으로 제공할 수 있으며 Kafka 기반 아키텍처에서 Kafka Connect, Kafka 를 활용하여 쉽게 CDC 이벤트를 스트리밍 할 수 있다는 장점이 있습니다. 다만 Kafka 인프라가 따로 없는 경우 구축이 필요하여 시스템 복잡도가 높아질 수 있다는 단점이 있습니다.
Flink CDC 의 경우 Apache Flink 에서 소스 커넥터로 사용할 수 있는데 Kafka 없이 직접 Log 를 읽어 저지연으로 실시간으로 처리할 수 있다는 장점이 있습니다. 그러나 이 또한 Flink 를 따로 구축할 필요가 있으며 Debezium 보다 성숙도가 낮다는 단점이 있습니다.
이미 Kafka 인프라가 존재한다는 점, CDC 이벤트를 수집하고 통합하는 것이 목적인 점을 고려하여 상대적으로 안정적인 Debezium 을 선정하게 되었습니다.
CDC 파이프라인 아키텍처 설계
앞서 CDC Tool 로 Debezium 을 선정하였기 때문에, 이를 운영하기 위한 Kafka 기반 아키텍처를 설계해야 했습니다. Debezium 은 단독으로 동작하는 구조가 아니라 Kafka Connect 위에서 Source Connector 형태로 실행되며, CDC 이벤트를 Kafka 로 전송하는 구조입니다. 따라서 안정적인 CDC 수집을 위해 Kafka Connect 클러스터를 먼저 구성해야 했습니다.
1. Kafka Connect 클러스터 배포
1) Kubernetes 기반 Kafka Connect 운영
Kafka Connect 클러스터는 Kubernetes 환경 위에 Strimzi Operator를 통해 배포하였습니다. Strimzi는 Kubernetes 상에서 Kafka 및 Kafka Connect를 Custom Resource(CR) 형태로 선언적으로 관리할 수 있도록 지원하는 Operator입니다. 이를 통해 인프라와 애플리케이션 구성을 코드로 정의하고, GitOps 기반으로 운영할 수 있습니다.
Strimzi 도입을 통해 다음과 같은 이점을 확보하였습니다.
- Kafka Connect 클러스터의 선언적 관리
- Connector 배포 및 스케일 조정 자동화
- 장애 복구 및 롤링 업데이트 용이
- GitOps 기반 운영 체계 구축
즉, Kafka Connect를 단순 애플리케이션이 아니라 쿠버네티스 리소스처럼 관리 가능한 컴포넌트로 운영할 수 있도록 설계하였습니다.
2) Distributed Mode 구성
Kafka Connect는 Distributed Mode 로 구성하여 다수의 Worker가 Connector Task를 분산 처리하도록 설계하였습니다.
이 구성의 주요 목적은 다음과 같습니다.
- Worker 장애 발생 시 Task 자동 재배치
- 수평 확장을 통한 처리량 증가
- 특정 Connector에 부하가 집중되는 현상 완화
이를 통해 단일 노드 장애가 전체 CDC 파이프라인 중단으로 이어지지 않도록 고가용성을 확보하였습니다.
3) Converter 전략: JsonConverter 선택
Kafka Connect의 데이터 직렬화 방식으로는 JsonConverter 를 사용하였습니다. 일반적으로 Schema Registry를 운영하는 환경에서는 Avro 기반 직렬화를 위해 AvroConverter를 사용할 수 있습니다. 이 경우 데이터 크기를 줄이고 스키마 진화를 체계적으로 관리할 수 있다는 장점이 있습니다. 다만, 본 아키텍처에서는 다음과 같은 판단 기준에 따라 JsonConverter를 선택하였습니다.
- 별도의 Schema Registry 운영 부담 제거
- 최소 구성으로 CDC 파이프라인 구축
- “가공”이 아닌 “이동” 중심의 단순 파이프라인 지향
즉, 스키마 강제 관리보다는 운영 복잡도 최소화와 단순성을 우선시한 선택입니다.
4) Kafka Connect 내부 토픽 설정
Kafka Connect는 내부적으로 다음과 같은 토픽을 사용합니다.
- config topic
- offset topic
- status topic
이들 내부 토픽의 Replication Factor를 3으로 설정하여 내결함성을 확보하였습니다.
이를 통해:
- 브로커 장애 시에도 Offset 및 Connector 상태 정보 보존
- Worker 재기동 시 안정적인 상태 복구
- CDC 파이프라인의 신뢰성 강화
즉, 데이터 토픽뿐만 아니라 Connect 메타데이터 토픽의 안정성까지 고려한 구성입니다.
2. Debezium Connector 배포
Kafka Connect 클러스터 준비 이후, MySQL 및 PostgreSQL의 CDC(Change Data Capture) 수집을 위해 Debezium Source Connector 를 배포하였습니다. Connector 배포는 Strimzi의 KafkaConnector Custom Resource를 활용하여 선언적으로 정의하였으며, 해당 리소스는 Git으로 관리하고 Argo CD를 통해 자동 배포하였습니다. 이를 통해 Connector 역시 애플리케이션이 아닌 인프라 리소스처럼 GitOps 방식으로 관리할 수 있도록 구성하였습니다.
1) KafkaConnector 기반 선언적 배포
KafkaConnector CR을 통해 다음을 코드로 정의하였습니다.
- Connector 클래스 (Debezium MySQL / PostgreSQL)
- 수집 대상 데이터베이스 및 테이블
- Kafka 토픽 네이밍 전략
- Snapshot 및 Streaming 관련 옵션
- Task 개수 및 병렬 처리 설정
이 방식의 장점은 다음과 같습니다.
- Connector 설정 변경 이력 추적 가능
- 환경(dev/stage/prod) 별 설정 분리 용이
- 수동 REST API 호출 없이 자동 배포
- 장애 발생 시 재적용을 통한 복구 단순화
즉, Connector 운영을 애플리케이션 배포 프로세스에 통합한 구조입니다.
2) CDC 이벤트 수집 흐름
Connector가 배포되면 Kafka Connect Worker 상에서 Task가 실행되며, 다음과 같은 흐름으로 동작합니다.
- Debezium이 DB의 binlog (MySQL) 또는 WAL (PostgreSQL)을 구독
- 변경 이벤트를 CDC 이벤트로 변환
- 테이블 단위로 Kafka Topic 자동 생성
- 각 Topic으로 실시간 이벤트 적재
결과적으로, 테이블 단위의 변경 이벤트 스트림이 Kafka 상에 생성되며 이후 스트리밍 처리나 적재 파이프라인에서 이를 활용할 수 있도록 설계하였습니다.
3) Snapshot 전략: snapshot.mode = no_data
Debezium의 주요 설정 중 하나인 snapshot.mode는 no_data로 설정하였습니다.
이는 다음을 의미합니다.
- Debezium 초기 Snapshot 비활성화
- Connector 시작 시점 이후의 변경 데이터만 스트리밍 수집
- 과거 데이터는 Debezium이 직접 읽지 않음
일반적으로 Debezium은 초기 구동 시 테이블 전체를 Snapshot으로 읽은 후, 이후 변경 데이터를 스트리밍합니다. 그러나 본 아키텍처에서는 다음과 같은 이유로 Snapshot 기능을 사용하지 않았습니다.
- 대용량 테이블에서 Snapshot 수행 시 DB 부하 증가
- Snapshot + Streaming 이중 처리 복잡도
- Snapshot과 Streaming 간 일관성 관리 부담
4) Snapshot은 Spark로 별도 구현
초기 데이터 적재는 Debezium이 아닌 Apache Spark 기반 배치 작업으로 별도 구현하였습니다.
이 전략의 핵심은 다음과 같습니다.
- Snapshot과 Streaming 경로를 분리
- 대량 데이터 적재는 Spark의 병렬 처리로 수행
- CDC는 “순수 변경 이벤트 스트림” 역할에 집중
이를 통해 Debezium은 변경 이벤트 수집에만 집중하도록 역할을 단순화하였고, 초기 데이터 적재는 Spark 기반 데이터 플랫폼에서 통제 가능하도록 설계하였습니다.
결과적으로 Snapshot과 Streaming을 명확히 분리함으로써,
각 단계의 책임을 분리하고 운영 복잡도를 낮추는 아키텍처를 구성하였습니다.
3. Spark Structured Streaming 을 통한 CDC 데이터 수집
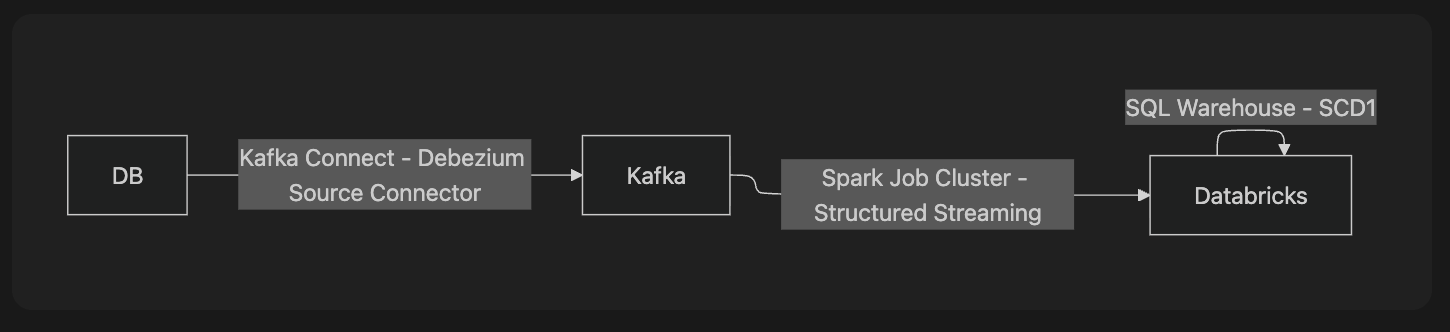
Debezium을 통해 생성된 CDC 이벤트는 Kafka Topic에 적재되며, 이를 데이터 플랫폼으로 통합하기 위해 Apache Spark Structured Streaming 을 활용하여 수집하였습니다. 최종 적재 대상은 Databricks 상의 Delta Table입니다.
1) 200개 이상의 토픽을 동적으로 수집하는 구조
실제 서비스(Product)가 다수 존재하여 DB 인스턴스가 여러 개였고, 그 결과 Debezium이 생성한 Kafka Topic 수가 200개 이상으로 증가하였습니다. 또한, 신규 테이블이 추가될 때마다 새로운 Topic이 생성되었기 때문에 토픽을 개별적으로 명시하는 방식은 유지보수 비용이 매우 높았습니다. 이를 해결하기 위해 Structured Streaming의 subscribePattern 옵션을 활용하였습니다.
- 특정 네이밍 패턴을 만족하는 모든 Topic 자동 구독
- 신규 Topic 생성 시 코드 수정 없이 자동 수집
- 토픽 증가에 유연하게 대응 가능한 구조 확보
즉, 토픽 수 증가를 전제로 한 확장형 수집 아키텍처로 설계하였습니다.
2) 실시간 대신 Available Now 기반 마이크로배치 전략
CDC 파이프라인이 반드시 실시간으로 동작할 필요는 없었기 때문에 지속 실행 스트리밍 대신 availableNow=True 옵션을 활용하였습니다. 해당 옵션을 통해 다음과 같은 기능을 수행할 수 있었습니다.
- 실행 시점까지 쌓인 데이터를 한 번에 처리
- 처리 완료 후 종료
- 스트리밍 API를 사용하지만 실제로는 배치 형태로 동작
실행은 Apache Airflow 를 통해 주기적으로 트리거하여 운영하였습니다.
이 전략을 통해:
- 상시 클러스터 유지 비용 절감
- 리소스 사용 시간 최소화
- CDC 증분 반영은 유지
라는 비용 효율적인 구조를 구성하였습니다.
3) Checkpoint 기반 Offset 관리 및 증분 처리
Structured Streaming 의 checkpointLocation 을 지정하여 Kafka Offset 을 관리하였습니다.
이를 통해:
- 각 Topic별 마지막 처리 Offset 저장
- 장애 발생 시 마지막 지점부터 재처리
- 중복 최소화 및 안정적인 증분 처리
Debezium → Kafka → Spark → Delta로 이어지는 흐름에서 신뢰성 있는 Incremental 파이프라인을 구성하였습니다.
4) 단일 CDC 통합 테이블 설계
수집된 CDC 이벤트는 테이블별로 분리 저장하지 않고, 단일 CDC Raw Table 에 통합 저장하는 구조로 설계하였습니다.
이 구조의 장점은 다음과 같습니다.
- 수집 레이어 단순화
- 신규 테이블 추가 시 별도 물리 테이블 생성 불필요
- 이후 가공 레이어에서 유연하게 파생 테이블 생성 가능
즉, 수집 단계에서는 “표준화된 이벤트 저장소” 역할만 수행하도록 하였습니다.
5) SCD1 증분 처리를 고려한 Liquid Clustering 적용
이후 CDC 통합 테이블을 소스로 사용하여 여러 SCD1 테이블을 생성하였으며, 이 과정에서도 증분 처리가 필요하였습니다. SCD1 처리 시 일반적으로 다음과 같은 조건이 자주 사용됩니다.
- 특정 Topic(= 특정 원천 테이블) 필터
- 적재 시간 기준 증분 필터
이를 최적화하기 위해:
- 토픽 컬럼
- 적재 시간 컬럼
에 대해 Liquid Clustering 을 적용하였습니다.
이를 통해:
- 특정 Topic만 조회할 때 Data Skipping 효과 극대화
- 적재 시간 범위 조건 처리 시 I/O 최소화
- SCD1 Merge 작업 성능 개선
즉, 단순히 데이터를 저장하는 것이 아니라 후속 증분 처리 패턴을 고려하여 물리적 레이아웃을 설계하였습니다.
6) 아키텍처 관점에서의 의미
이 설계는 다음을 전제로 합니다.
- 토픽 수는 계속 증가한다
- 완전 실시간은 필요 없다
- 수집 레이어는 단순해야 한다
- 가공 레이어에서 다양한 파생 테이블이 생성된다
그 결과:
- subscribePattern을 통한 확장성 확보
- availableNow 기반 비용 최적화
- checkpoint 기반 안정적 증분 처리
- Liquid Clustering을 통한 후속 SCD 성능 최적화
라는 구조로 CDC 파이프라인을 구성하였습니다.
4. SCD1 테이블 생성
CDC 이벤트를 **Databricks**로 통합한 이후, 이를 기반으로 SCD Type 1 테이블을 구성하였습니다.
전체 흐름은 다음과 같습니다.
- Spark 기반 Snapshot으로 초기 테이블 생성
- 이후 CDC 이벤트를 MERGE 방식으로 지속 반영
- UPSERT 및 DELETE를 통해 최신 상태 유지
1) 초기 Snapshot 기반 테이블 생성
Debezium Snapshot을 사용하지 않았기 때문에, 초기 적재는 Apache Spark 기반 배치 작업으로 직접 수행하였습니다.
이를 통해:
- 대용량 테이블 병렬 처리
- DB 부하 통제 가능
- Snapshot 시점 명확화
Snapshot 완료 이후부터는 CDC 이벤트를 통해 변경분만 반영하는 구조로 전환하였습니다.
2) CDC 이벤트 기반 SCD1 MERGE 전략
CDC 통합 테이블에는 Insert / Update / Delete 이벤트가 모두 포함되어 있습니다. 이를 SCD1 테이블에 반영하기 위해 MERGE INTO 구문을 사용하였습니다.
처리 단계는 다음과 같습니다.
(1) Schema 결정 및 Parsing 전략
CDC 이벤트는 JSON 기반으로 저장되어 있었기 때문에,
정확한 스키마를 정의한 후 Parsing 과정이 필요했습니다.
이를 위해:
- CDC 이벤트의 적재 시간 기준 최신 데이터 샘플링
- 해당 시점의 이벤트를 기반으로 스키마 추론
- 이후 전체 CDC 이벤트 Parsing
방식으로 처리하였습니다. 즉, 가장 최신 스키마를 기준으로 테이블 구조를 결정하는 전략입니다.
(2) Row 단위 최신 상태 추출
SCD1은 “최신 상태만 유지”하는 모델이므로,
- Primary Key 기준
- 가장 최신 이벤트만 선택
- Delete 이벤트는 삭제 처리
과정을 거친 후 MERGE를 수행하였습니다.
(3) SQL Warehouse 기반 MERGE 수행
MERGE 구문은 Spark Cluster가 아닌 Databricks의 Databricks SQL Warehouse를 통해 실행하였습니다.
그 이유는 다음과 같습니다.
- 데이터 양이 상대적으로 크지 않음
- Spark Job 기동 오버헤드가 큼
- 클러스터 상시 유지 비용 비효율적
SQL Warehouse는 OLAP 엔진 기반으로 빠르게 쿼리를 수행할 수 있기 때문에, 주기적으로 실행되는 SCD1 MERGE 작업에 더 적합하다고 판단하였습니다.
결과적으로:
- 리소스 낭비 최소화
- 실행 지연 시간 단축
- 운영 비용 최적화
를 달성하였습니다.
3) Schema Evolution 대응 전략
운영 중 원천 DB의 컬럼이 추가될 가능성을 고려하여 Schema Evolution을 자동으로 허용하도록 설정하였습니다.
이를 통해:
- 신규 컬럼 자동 추가
- 수동 DDL 작업 최소화
- CDC 기반 구조 변경에 유연하게 대응
즉, 스키마 변경이 발생해도 파이프라인이 중단되지 않도록 설계하였습니다.
4) 전체 아키텍처 관점에서의 의미
이 SCD1 구조는 다음과 같은 특징을 가집니다.
- Snapshot과 CDC의 역할 분리
- CDC 통합 테이블 → 목적별 SCD 테이블 파생 구조
- MERGE 기반 최신 상태 유지
- SQL Warehouse 활용을 통한 비용 최적화
- Schema Evolution을 고려한 장기 운영 설계
결과적으로, 단순한 CDC 적재를 넘어 운영 가능한 데이터 모델로 안정적으로 정제하는 레이어를 구성하였습니다.
결과
본 CDC 아키텍처를 통해 현재 200개 이상의 테이블에 대해 안정적으로 변경 데이터 파이프라인을 운영하고 있습니다. 초기 설계 단계에서 고려했던 확장성 전략 (동적 토픽 수집, 단일 CDC 통합 테이블, Snapshot과 CDC 경로 분리) 이 실제 운영 환경에서도 효과적으로 작동하였으며, 신규 테이블이 추가되더라도 다음과 같은 절차로 빠르게 반영할 수 있게 되었습니다.
- Spark 기반 Snapshot 수행
- CDC 이벤트 스트리밍 연결
- SCD1 MERGE 적용
이 구조 덕분에 별도의 파이프라인 추가 개발 없이, 기존 프레임워크 내에서 테이블을 확장할 수 있는 체계를 갖추게 되었습니다.
운영 성과
- 관리 대상 테이블: 200개 이상
- 신규 테이블 온보딩: Snapshot + CDC 병합 방식으로 신속 반영
- 평균 데이터 제공 지연 시간(Latency):
- 기존 약 30분
- 현재 약 10분
즉, 단순히 테이블 수가 증가한 것이 아니라 운영 복잡도는 통제하면서 데이터 제공 속도는 약 3배 개선하였습니다.
또한,
- 동적 토픽 구독 구조
- 마이크로배치 기반 비용 최적화 전략
- SQL Warehouse 기반 MERGE 처리
- Liquid Clustering을 통한 증분 처리 최적화
등의 설계 선택이 실제 성능 및 운영 효율 개선으로 이어졌습니다.
이제 남은 과제는 단순히 “빠르게 제공하는 것”이 아니라, “정확하게 제공하고 있는지 검증하는 것”입니다. 다음 포스팅에서는 이 CDC 파이프라인의 신뢰성을 보장하기 위한 정합성 검증 전략에 대해 다루어보겠습니다.
'Data' 카테고리의 다른 글
| [Redash] docker -> EKS 기반 마이그레이션 (0) | 2024.08.26 |
|---|